Researcher protocol
The researcher or the research center, engages in a confidentiality agreement with the company holding the ROGER software while respecting the rights and duties of the researchers and participants.
If the researcher or the research center wishes to work with ROGER he can contact the clinical expert and scientific manager of the project : S.SERLET ([email protected]).
The objective is to create, as a first step, a privileged partnership with the research centers. They will be able to use R.O.G.E.R and develop their own scenarios (evaluation, rehabilitation, stimulation or other) in order to be able to propose them in preview. These scenarios will eventually be available to practitioners or users.
Subsequently the purchase of a license will provide the following interface:
If the researcher or the research center wishes to work with ROGER he can contact the clinical expert and scientific manager of the project : S.SERLET ([email protected]).
The objective is to create, as a first step, a privileged partnership with the research centers. They will be able to use R.O.G.E.R and develop their own scenarios (evaluation, rehabilitation, stimulation or other) in order to be able to propose them in preview. These scenarios will eventually be available to practitioners or users.
Subsequently the purchase of a license will provide the following interface:
- environment
- scenario editor
- data generated by users
Data
The R.O.G.E.R software allows the collection of data (BigData) that can be exploited during the evaluation, or a posteriori. Indeed, the data generated by the game are numerous and do not all allow to obtain scores or analyzes. The current functioning of the research is said "a priori". Researchers formulate hypotheses that are or are not verified by experimentation. When establishing evaluation practices, we form the following hypothesis: the subject will or will not behave similarly to a majority of the tested population. Depending on the results, it will or will not be in the expected standard. However, many data can not be analyzed (not captured or irrelevant at first). R.O.G.E.R will keep his data to create "a posteriori" analyzes.
From there, the analyzes via algorithms developed in AI (artificial intelligence) will make it possible to create correlations more and more precise as the data flock. These data will allow the AI to propose working hypotheses and thus to find a qualitative explanation to the data.
This process is not widely used in the field of research because it requires a lot of data that is not accessible through traditional collection channels. Virtual reality and data collection (BigData) can collect a lot of data and speed up the collection and analysis of data.
This process is not widely used in the field of research because it requires a lot of data that is not accessible through traditional collection channels. Virtual reality and data collection (BigData) can collect a lot of data and speed up the collection and analysis of data.
What Data ?
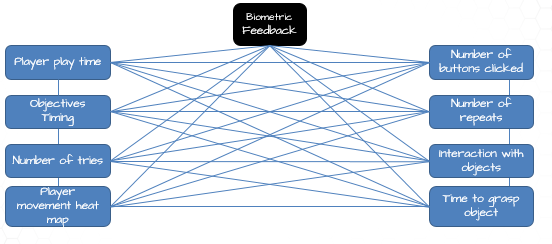
The previous diagram shows the data as it is available. The raw data is a timeline (we record the player's positions every second and we also record each trigger). Thus, we can obtain latency between information and action, the time taken to press a trigger, the number of tests ... These data can be multiplied as needed.
We were talking about data generated by the game and by the player. To this information can be added biological feedback. Many authors agree that cognition can be accessed through biological information. The processing of this information is possible via R.O.G.E.R. The latter being projected on a screen, all biological information readout interfaces are possible. We can therefore imagine incorporating an eye-tracker (measuring the position of the eyes on the screen), an empatika bracelet (recording of the heart rate, body temperature), an EEG (reading of the waves of the brain). .. as many possibilities as there are machines that can provide details on the cognitive state.
By combining everything, we arrive at multiple combinations and a large number of possible correlations. All of this makes R.O.G.E.R unique software for great analysis and discoveries on human cognition.
We were talking about data generated by the game and by the player. To this information can be added biological feedback. Many authors agree that cognition can be accessed through biological information. The processing of this information is possible via R.O.G.E.R. The latter being projected on a screen, all biological information readout interfaces are possible. We can therefore imagine incorporating an eye-tracker (measuring the position of the eyes on the screen), an empatika bracelet (recording of the heart rate, body temperature), an EEG (reading of the waves of the brain). .. as many possibilities as there are machines that can provide details on the cognitive state.
By combining everything, we arrive at multiple combinations and a large number of possible correlations. All of this makes R.O.G.E.R unique software for great analysis and discoveries on human cognition.
And data protection ?
|
European legislation imposes rules on the protection of clinical data on the internet and in current practice.
With R.O.G.E.R, data protection is ensured. Indeed, the data you will provide can not allow identification (via openClinica opensource clinical data management software developed in the context of pharmaceutical trials). In addition, the data is plotted until processed and returned. In a clinical setting, only the therapist will be able to anonymize the data from his own file. We meet the requirements of the GDPR to ensure that no one can access confidential and medical data. Only raw data is retained. We keep every trace of possible changes to ensure their authenticity at every step. |

|
Towards real-time normalization
One of the strengths of R.O.G.E.R is the ability to design algorithms to update normative data in real time. Each use of the software or scenario performed will offer a lot of data. This data can then be used to feed the AI to propose new data in the standards.
In this way, if an evaluation is proposed, when it is standardized, it may be that the latter does not have a cohort large enough to create more groups. From samples of larger populations (age, gender, socio-professional category ...), it will then be possible to create more precise standards and more adapted to each user.
In this way, if an evaluation is proposed, when it is standardized, it may be that the latter does not have a cohort large enough to create more groups. From samples of larger populations (age, gender, socio-professional category ...), it will then be possible to create more precise standards and more adapted to each user.
